2.3. Spatial structure of the triplet genetic
code
In the first version of our
page, and also in publications [4] the term «topological structure» of the genetic
code has been used. This term reflects the relationship of the genetic code with the topology of the encoded protein structures. Not refusing from this term, in the sequel we will often use the term
“spatial structure” of the genetic code, as more common. We already mentioned on the first page that some variants
of spatial structure of the triplet code
were offered. Detailed analysis of these variants is made in [6-8]. Let's continue the story about of the
genetic code, having passed to detailed
consideration of procedure of construction of spatial structure of the triplet genetic code and features of its
structural organization.
2.3.1. Stages of construction of
the spatial structure of the triplet genetic code
The spatial structure of the triplet genetic code has been constructed just as well as the doublet
code, on the basis of the principle of single substitutions of bases in the triplets (the principle of single transitions).
|
Each base of the triplet can be connected by single transitions with the three other bases. |
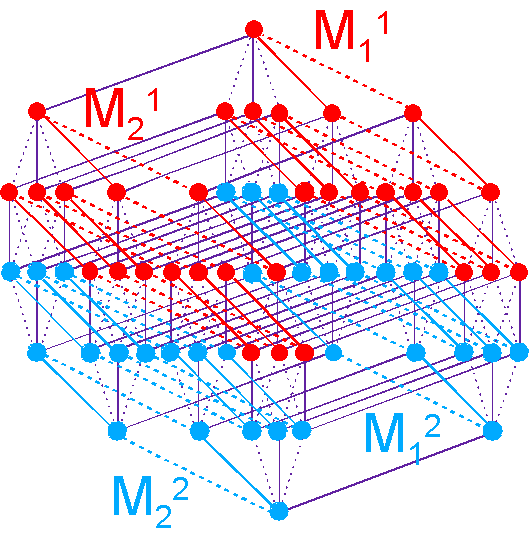
The result of this work
was the structure that is
isomorphic to the Boolean hypercube
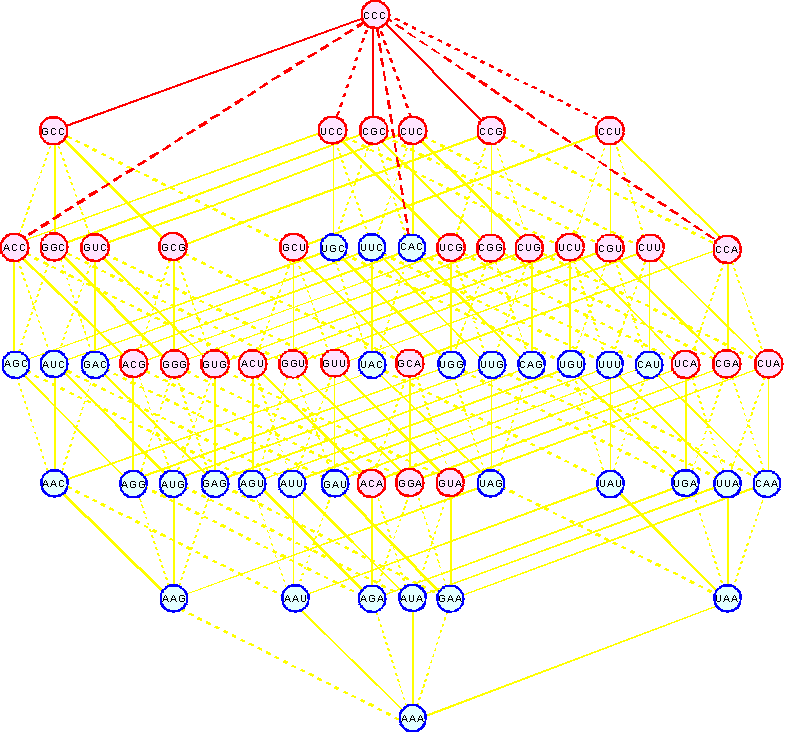
B6. |
On this structure nine triplets originating from the ССС
(3 C base substitution
at each position of the triplet),
and their relationships are shown in red. It is L-structure
of the Boolean
hypercube.
Triplets with substitutions in the first position are located at the
left. There is also a D-structure
symmetric to it in which triplets with replacements in the first position are
located on the right side of a hypercube. The spatial
structure of the genetic code containing
transitions C<-->G, U<-->A, C<-->U, G<-->A and superimposed on it transitions C<-->A, U<-->G is a
nine-dimensional simplex. |
|
|
||
|
Fig.
9. The spatial structure of the triplet genetic code, which is isomorphic to the Boolean hypercube B6. |
||
Let's try to understand this "abracadabra".
2.3.2.
Features
of the structural
organization of the triplet genetic
code
The structure of the triplet genetic code inherited several properties from the hypercube B6.
In addition, it has its own, characteristic for a triplet code, properties, namely: single transitions, an
arrangement of the triplets encoding the similar amino acids, Rumer’s transformation. We
will consider them in more detail.
|
2.3.2.1. Properties of the structure of the triplet genetic code, inherited from the B6 hypercube |
|||||
|
A. Longlines |
Longlines |
Triplets |
|||
|
The spatial structure
of the triplet genetic code contains |
|
I II III IV V VI VII |
1 6 15 20 15 6 1 |
||
|
Fig.
10. Longlined structure of the triplet genetic code. |
|||||
|
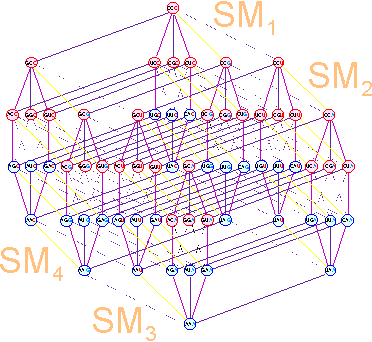
B. Hierarchical Organization |
|||||
|
|
|
|
|||
|
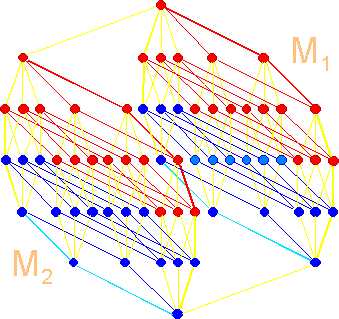
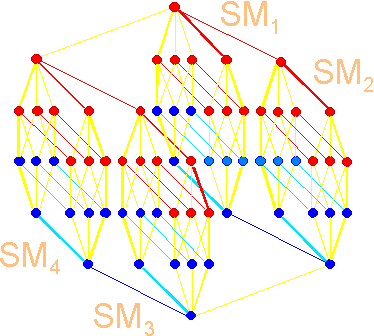
Fig.
11. The hierarchical organization of
the spatial structure of the genetic
code. |
|||||
|
2.3.2.2.
The specific
properties of the spatial structure of the genetic code |
|||
|
A. The single transitions |
|||
|
In
Figure 9 possibility
of formation of three types of transitions for each of three bases of
triplets is shown: C<-->G, U<-->A between complementary bases (solid lines); C<-->A, G<-->U between non-complementary
bases (rare dotted line); C<-->U, G<-->A transitions pyrimidine - pyrimidine and purine
- purine (frequent dotted lline). In practice, in a general form on the presented model it is possible to
consider only two types of transitions: C<-->G, U<-->A и C<-->U, G<-->A. The third type of
transitions C<-->A, G<-->U which is an imposition on the initial structure, for technical reasons
in a general view is difficult to portray, therefore they are
presented in an enlarged view in separate drawing (see transitions C<-->A, G<-->U). |
|||
|
Single transitions C<-->G, U<-->A |
|||
|
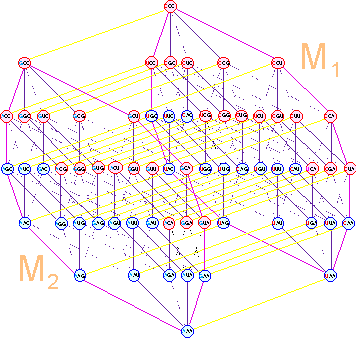
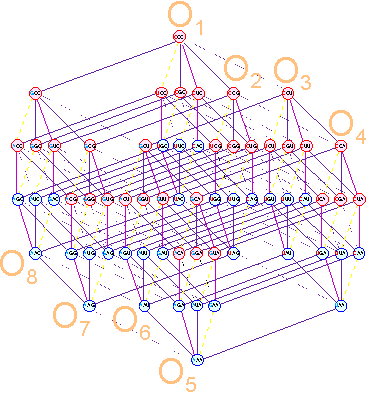
In the first position of the triplet these transitions occur between two sets (M1 и M2) and are shown in Figure 12 a. In the second position
of the triplet they are formed in octets (Fig. 12 b). In the third position of the triplet, these transitions connect the adjacent octets within subsets (Fig. 12 c). If necessary, they can be seen in more detail, having clicked
the underlined words in each line
in the caption under the picture
12 or pictures themselves. |
|||
|
|
|
|
|
|
Fig. 12. Single transitions of C<-->G, U<-->A (solid lines). |
|||
|
Single transitions C<-->U, G<-->A |
|||
|
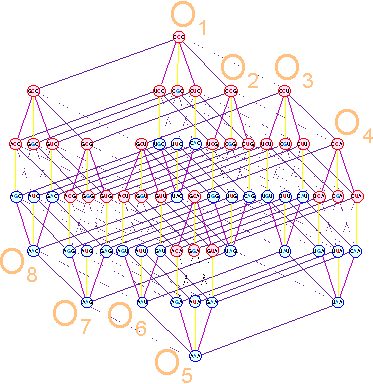
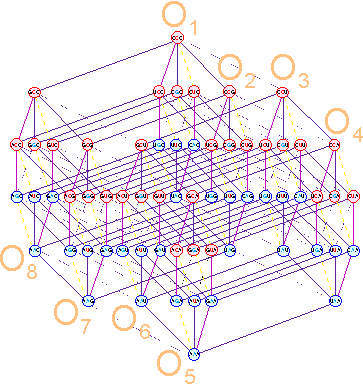
In the first position transitions of this type
are observed within the octet of triplets down from right to left. They are shown in Figure 13 a. In the second position, on the contrary, they connect triplets
in octets from
top to bottom from left to right (Fig. 13 b). Finally, in the third position of triplet, these
transitions connect subsets of triplets SM1 - SM2 and SM4 -
SM3 (Fig. 13 c). If necessary,
as for Figure 12, you can view them
in more detail, having clicked
the underlined words in each line
in the caption under the picture
13 or pictures themselves. |
|||
|
|
|
|
|
|
Fig. 13. Single transitions of C<-->U,т G<-->A (frequent dashed
line). |
|||
|
It is known that in the Boolean hypercube
В6 each vertex is connected
to six neighbors.
Shown above, six
different single transition,
actually,
make up the structure of the triplet
genetic code, which is isomorphic to
the Boolean hypercube В6. |
|||
|
Single transitions C<-->A, G<-->U (see separate Figure 14). |
|||
|
B. An arrangement of the triplets coding for similar amino acids |
|||
|
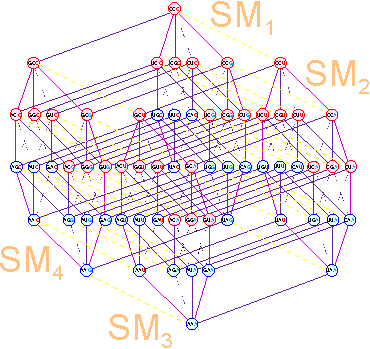
On the spatial structure of the
genetic code triplets coding
for similar amino acids form
either a quartets, or a pair of triplets occurring in quartets. The quartets
of triplets which encode the same amino acid, derived from «red
doublets», are marked
in red (Fig.
15) and are located in the top part of each set: M11 and M21. Quartet of triplets, which are usually encoded by only two pairs of amino
acids derived from the "dark blue doublets" are marked in blue
(Fig. 15) and are located at the bottom of each of the sets of the hypercube: M12 and M22. To
see them in more detail, click the underlined capital letters of the text. |
|
||
|
Fig. 15. An arrangement of quartets of triplets coding for similar amino acids on spatial structure of
a genetic code. |
|||
|
C. Rumer’s transformation |
|||
|
|
As seen in Figure 16,
the triplets of the groups are transformed in
CCC <---> AAA, CCU <---> AAG etc. |
||
|
Fig. 16. An arrangement of the triplets
connected by Rumers’s transformation, on the spatial structure of the genetic
code. |
|||
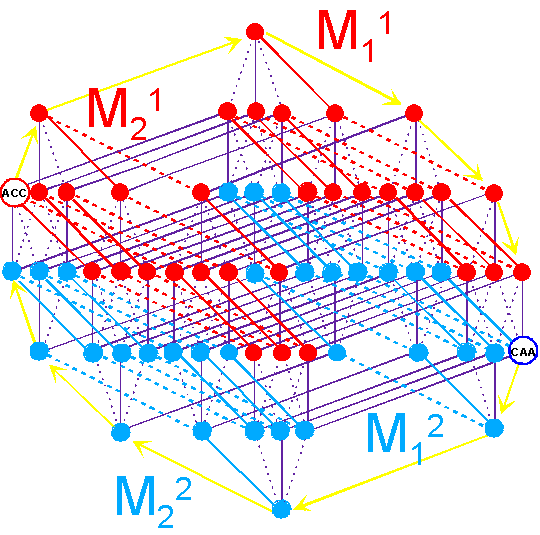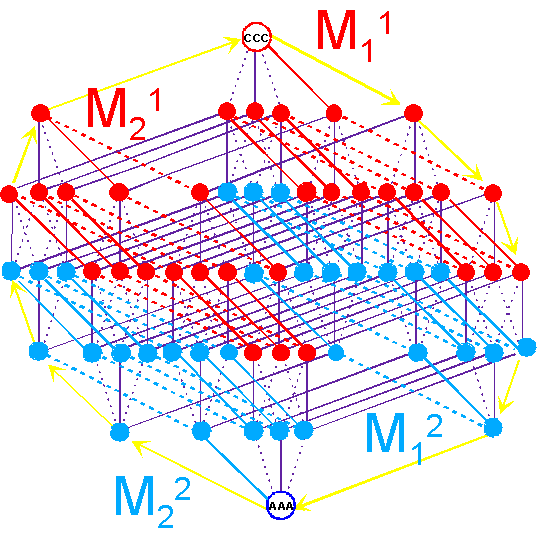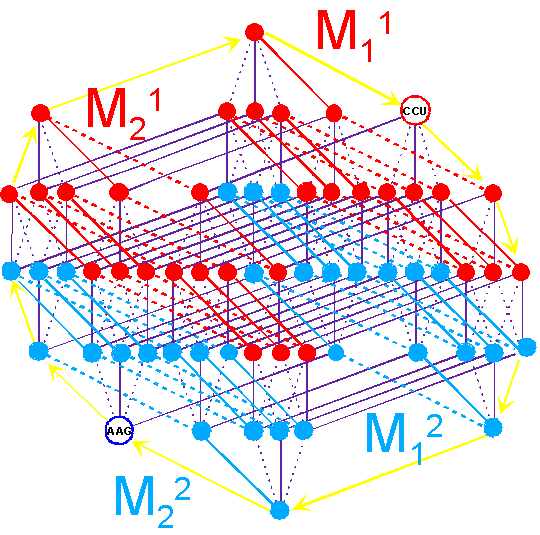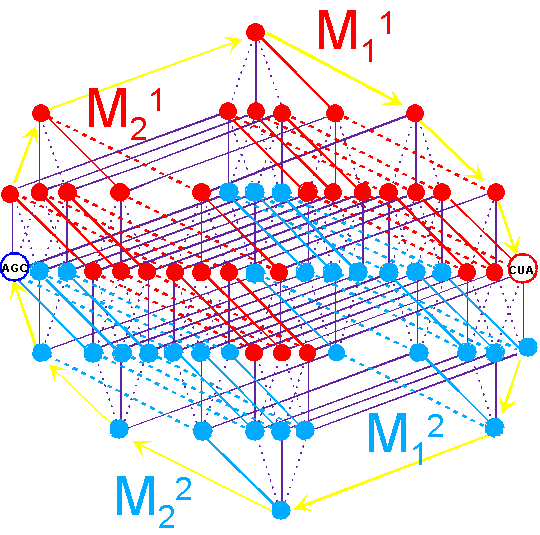
"Abracadabra" is over.
2.3.3. The
spatial structure of the triplet genetic code: the
results
It's time to admire the
full spatial structure of the
triplet genetic code, which is shown in Figure 17.
|
|
|
Fig. 17. The spatial structure of the triplet genetic code. |
|
We
summarize briefly all that we have
considered in this section. The spatial structure of the triplet genetic code
can be constructed on the basis of
single transitions of bases in
triplets. This structure is
isomorphic to the Boolean hypercube
B6, which can be seen
in Figure 17. This structure, as seen in this figure, inherited
from the B6 hypercube
longlines structure (7 longlines) and a
hierarchical organization (2 sets
M1 and M2
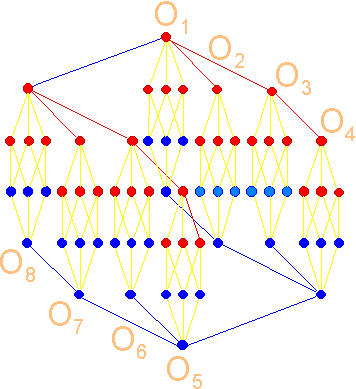
of 32 triplets, 4 subsets SM1 – SM4 of 16 triples and eight octets O1 – O8). The specific
properties of this structure also observed in Figure 17 are: - the presence
of single transitions between the bases of triplets which are easy for
tracking on this structure; - the existence of two groups of triplets
coding for similar amino acids,
forming a quartet or a pair belonging to quartets (quartets, red and blue); -
transformation of two groups of triplets each other by rule C <--> A, G <--> U (Rumer’s transformation)
and symmetry of these two groups in the structure. |
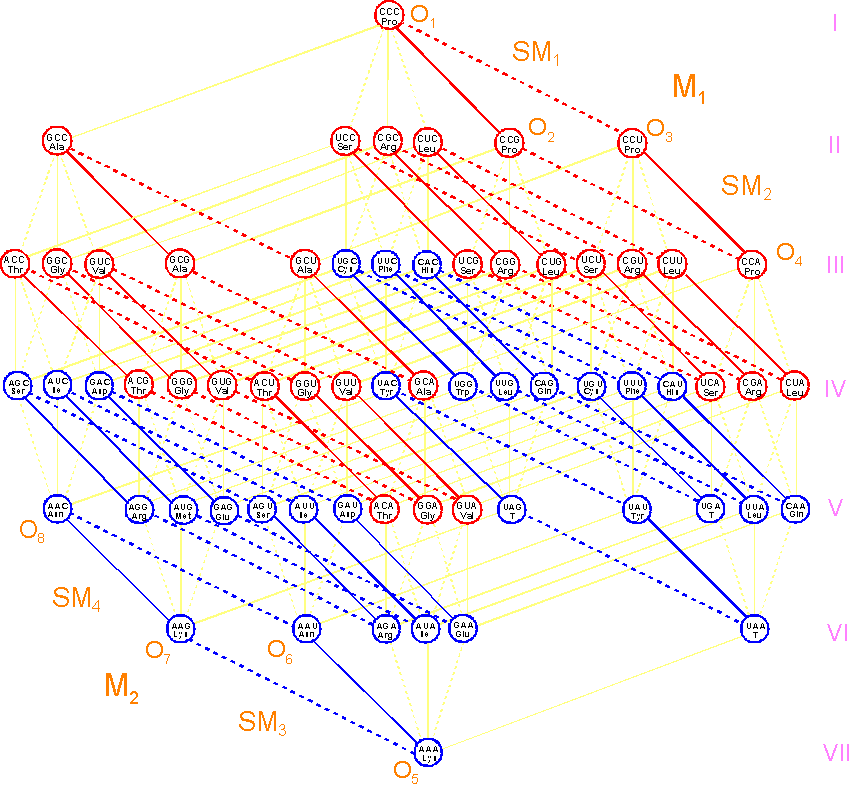
For those who wish to think about the code the spatial structure of the
triplet code on a white background
is presented. It is conveniently to print on your printer.
The following questions arise:
- why
the structure of the genetic code
is isomorphic to the Boolean hypercube В6?
- why amino acids are assigned to the given
triplets, instead of others?
- what explains the existence in the genetic code of two groups of amino acids, which are encoding by triplets related by Rumer’s transformation?
The theory of topological coding of
proteins is trying to answer these and other questions (Section 3).
The story of how the
spatial (topological) structure of a genetic code has been constructed,
read in V.A.Karasev's book
"The Genetic code: new horizons"