1.
The
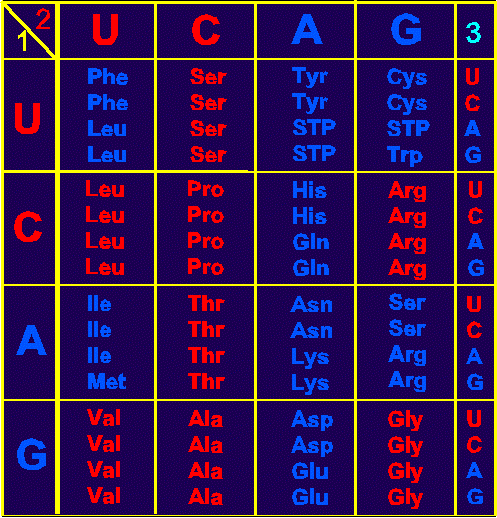
modern table of a genetic code
The common table of the genetic code,
proposed in the early 60s [10], significantly out of
date because it does not reflect all the complex relationship between coding
triplets and amino acids. Nevertheless, we will start with it, because to
further understanding we need to remember something.
Amino acids of proteins are encoded in
nucleic acids (DNA or RNA) in the form of triplets consisting of three nitrogen bases,
i.e. XYZ.
|
|
In the code table the first letters of
triplets (X) are located
at the left (sequence U,C,A,G), the second (Y), in the same sequence, - from above and the third (Z) - on the right in each cell. For example, phenylalanine (Phe), located at line one of the
first column is encoded
by triplet UUU. The table
shows that the column containing C in the second position, contains
in each cell four identical
amino acids (the "red" amino
acids), and column with A
in the second position - two identical values (" dark
blue"). However a clear division into two groups in the entire table it is
not observed, that reveals a rhombic variant of the genetic dictionary (section 2.1.). |